ES Module Shims started out as a way to use new native modules features on the web (like import maps) before they were released in browsers, in a way that could be suitable for fast development or simple production workflows.
Over time it has turned into a highly optimized production-suitable drop-in polyfill for import maps.
With import maps now supported by 70% of users and Firefox just announcing today it will be shipping work on import maps it's a good time to share the details of ES Module Shims and its approach more widely.
This post first goes into the background of the project architecture then describes how the polyfill mode came about, along with some comprehensive performance benchmarks, ending with some ideas of what might be on the future horizon for the project.
Thank you to Basecamp for seeing the potential of the project and sponsoring new performance investigation work on ES Module Shims, and to Rich Harris for the original inspiration for the project.
Loader Architecture
At its core ES Module Shims is a module loader. While script evaluation can be implemented as a simple one-argument eval()function, setting up a module loader is more complex. Modular evaluation requires the machinery for providing a module source, supporting dependency discovery and resolution from that source, then providing sources for those dependencies asynchronously in turn and continuing the process iteratively.
It doesn't help that there is no modular evaluation API on the web, at all. At the time ES Module Shims was created in 2018, all major browsers supported <script type="module">, but support for other features like dynamic import() or import.meta.url was still inconsistent.
To implement a feature like import maps requires customizing the module dependency resolution, so one needs some kind of loader hook to achieve this.
The initial problem for ES Module Shims was: How can we construct an arbitrary module loader with custom dependency and source text resolution on top of <script type="module">?
Achieving this isn't necessarily obvious but is made possible by two techniques:
- A small & fast module lexer
- Source customization via
BlobURLs
1. A small & fast JS module lexer
Given an arbitrary source text string, source, the first problem is to determine its import specifier positions.
For a source like
const source =
`import { dep } from 'dep';
console.log(dep, mapped);`;
we have an import 'dep' at position [21, 28] in the source string.
If we can determine the import positions, we can resolve those imports then use those same offsets to rewrite the source string via string manipulation:
const transformed = source.slice(0, 21) + '/dep-resolved.js' + source.slice(28);
To then get:
import { dep } from '/dep-resolved.js';
console.log(dep, mapped);
How to write an imports lexer?
If JS had been specified such that imports could only appear before other types of JS statements, then there would be no problem here. The issue is that the following is valid JavaScript:
const someText = `import 'not an import'`;
// import 'also not an import';
'asdf'.match(/import 'you guessed it'/);
import 'oh dear';
The above probably seem like silly edge cases, but when dealing with properly solving a problem for all cases, the edge cases have to be the focus.
While there are various import regular expressions that could be used to determine the import specifier positions, it's just not a reliable foundation to have for such a project since the problem with using a regex is that it cannot handle the language syntax edge cases consistently - one would always hit some module down the road that would fail analysis, breaking the entire workflow of reliably implementing a modular evaluation.
The other alternative would be to use a parser, but even the smallest parser at the time was over 100KB and not without significant performance overhead for this kind of use case.
Rich-Harris-Inspired Magic
When Rich Harris released Shimport (in what I imagine as a spurt of idle creativity over a couple of hours one weekend, before he moved on to building Svelte the next weekend), it demonstrated in-browser dependency analysis with a small and highly efficient JavaScript lexer suitable for quick development or even simple production workflows, something I never believed would have been possible.
Shimport uses a custom lexer to dynamically rewrite ES modules in the browser to support them in browsers without ES modules support.
Where Shimport reinterprets all imports and exports, the problem of just parsing imports and rewriting their inner strings seemed simple in comparison, and by using native modules live module bindings would naturally be supported.
Swapping notes with Rich over how to deal with the intricacies of the JS language, he shared the gist of the technique in handling one of the main concerns of writing a JS lexer without deeper parser knowledge - the regex division operator ambiguity problem.
Division Regular Expression Ambiguity
For most JS lexing the rules are quite simple - for a string you read from the first " to the last, handling escaping. Comments (/* and //) also follow a simple rule. Template expressions (`..${`..`}..`) have some nesting to deal with handled by nesting the parser function and regular expressions have some minor cases to check. Apart from that one can pretty much just match opening [, ( and { to their closing versions without much further parser context necessary.
Then if all the braces and parens are closed, we know we are at the top level, and we can start parsing imports using their grammar parser rules only to get a small module lexer.
But as soon as you hit a / there's a lexer ambiguity problem. For example:
while (items.length) /regexp/.test(items.pop()) || error();
What distinguishes the / as being a regex and not a division in the above is that the brace is the end of a while statement, but to know that requires complete parser knowledge of the while statement parser state.
The trick then is to create a minimal lexer context stack that matches opening and closing braces or parens with just enough state information to handle the major ambiguity cases like the above.
Determining if the parser is in an expression position for a dynamic import() (which otherwise could also be ambiguously with a class method definition) can be handled in a similar way with a minimal lexer context associated with the brace and paren stack.
Initially implemented as an embedded JS-based lexer in ES Module Shims, the implementation was later converted into C and compiled with WebAssembly (C compiles to one of the smallest Wasm outputs) for even further performance benefits (mostly cold start benefits actually, V8 isn't free!) and became the es-module-lexer project.
To give an idea of the performance, the whole project is a 4.5KB JS file that can analyze 1MB of JS code in under 10ms on most desktops with the performance roughly scaling linearly. It's become a popular npm package with over 7.5 million downloads a week. There's a lot of value to be found in sharing a good solution to a common problem.
2. Source customization via Blob URLs
Blob URLs can be used with dynamic import() to execute arbitrary module sources:
const blob = new Blob([
"export const itsAModule = true"
], { type : 'text/javascript' });
const blobUrl = URL.createObjectURL(blob);
const { itsAModule } = await import(blobUrl);
console.log(itsAModule); // true!
In browsers without dynamic import support, the same could be achieved by dynamically injecting a <script type="module">import 'blob:...'<script> tag into the DOM.
With all the pieces in place, to consider handling an entire module graph, say we have an application like:
<script type="importmap">
{
"imports": {
"dep": "/dep.js"
}
}
</script>
<script type="module" src="./app.js">&ls;/script>
Where '/app.js' contains:
import depA from 'dep';
export default ...
importing 'dep' which resolves in the import map to '/dep.js'
If we rewrite or customize the source for '/dep.js', we get a blob URL for 'dep', which must then be written into its corresponding import position in '/app.js' above. We then create a blob URL from this transformed app.js source and finally import that blob dynamically.

The final import('blob:site.com/72ac72b2-8106') then fully captures the entire graph execution of app.js, making ES Module Shims a comprehensive customizable loader on top of baseline native modules in browsers fully supporting live bindings and cycles (barring some minor fudging of live bindings in cycles).
Shim Mode
The original implementation was to use custom module-shim and importmap-shim script types:
<script type="importmap-shim">
{
"imports": {
"dep": "/packages/dep/main.js"
}
}
</script>
<script type="module-shim">
import dep from 'dep';
console.log(dep);
</script>
This would guarantee no conflicts with the native loader, with ES Module Shims using fetch() to process dependencies and then lazily rewrite the sources using es-module-lexer before inlining them as Blob URLs.
Polyfill Mode
In March 2021, Chrome shipped unflagged support for import maps. It then became an appealing prospect to use a full native import maps workflow, having ES Module Shims only apply when needed in browsers without import maps support.
When using import maps in unsupported browsers, a static error is thrown:

Since this is a static error (happening at link time, not a dynamic error at execution time), no modules will be executed at all. As a result, it is possible for ES Module Shims to execute the module graph itself through its own loader only when it fails native execution, and there would be no risk of duplicate execution. Depending on the browser, the fetch cache can be shared as well.
The polyfill pattern in ES Module Shims then becomes one of re-executing static failures. As long you are statically using the features that you want polyfilled, in a way that would always result in a static error in unsupported browsers, ES Module Shims will detect that and run the modules through its loader to polyfill.
Further, in browsers with comprehensive import maps support (or whatever baseline modules features are the current new hotness), there would be no need for ES Module Shims to even analyze the sources at all enabling a complete baseline passthrough.
The polyfill mode handling involves the following steps:
- Run feature detections for import maps and related modules features.
- If the browser supports all the modern features, nothing further needs to be done.
- Analyze the module sources through the loader fetch and lexer tracing, and determine if any of them use unsupported native features that would statically throw.
- If the module graph has been determined to have statically thrown based on the source analysis, go ahead and execute the module graph in the ES Module Shims loader.
69% of users hit the fast path where the browser already supports import maps, where ES Module Shims basically does zero work apart from feature detections.
And as a result, polyfill mode ends up being a highly performant approach to polyfilling modules features for older browsers only.
The simplest workflow then is just to use an import map from the start:
<script async src="https://ga.jspm.io/npm:[email protected]/dist/es-module-shims.js"></script>
<script type="importmap">
{
"imports": {
"app": "/app/main.js"
}
}
</script>
<script type="module">import 'app'</script>
By using an import map straight away, the immediate error in browsers without native support avoids unnecessary browser processing and ensures a clean polyfill switch.
Performance
To verify the performance, Basecamp sponsored some benchmarking and optimization work on ES Module Shims.
The goals of the performance work for ES Module Shims were to verify:
- Baseline passthrough: In browsers with import maps support, performance is exactly in line with native loading.
- Polyfill performance: To quantify the polyfill loading cost in browsers without import maps support.
- Import maps performance: To investigate the performance of large import maps with many modules.
Benchmark Setup
All of the performance tests use a simple component rendering using Preact, and include the full load time of the page. Each sample n includes a component and Preact loading and executing, and thus corresponds to the comprehensive execution of ~10KB of JS code loading and interacting with the DOM. By n = 100, 1MB of code is being loaded and executed (10KB per sample). All scenarios below are based on uncached performance with varied network settings as descibed per case.
The benchmark results and code are available on the ES Module Shims repo. Multiple runs are performed using Tachometer. Tests were performed on a standard desktop machine.
Baseline Passthrough Performance
In this case, the goal is verify that loading ES Module Shims polyfill for the ~70% of users with import maps support will not cause any unnecessary slowdowns and match native performance.
To verify this, the benchmark compares using import maps to load n samples of preact + a component render loading and executing them in parallel in Chrome with and without the ES Module Shims script tag on the page
The benchmarks include the full time to load ES Module Shims into the browser and run the feature detections.
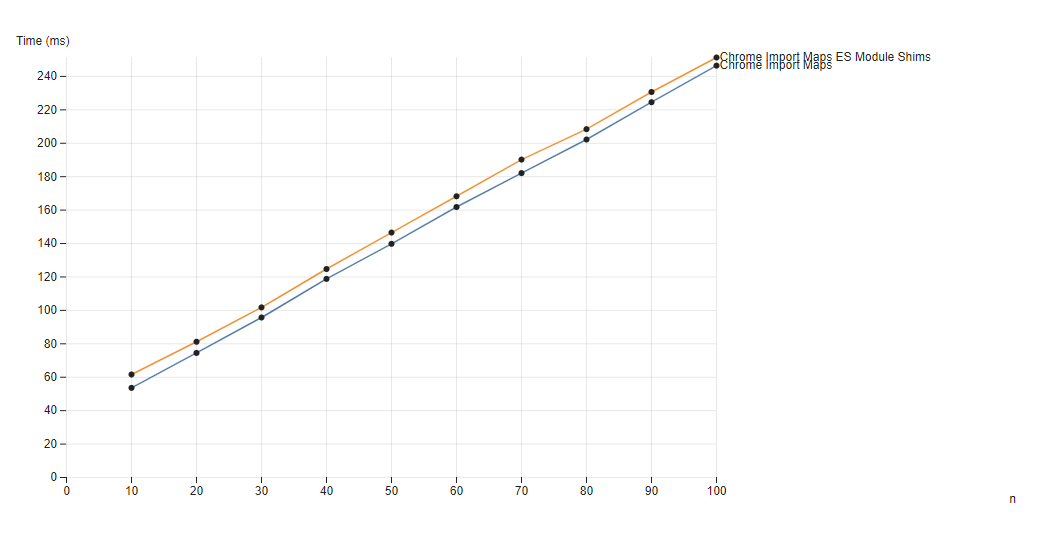
n number of samples loadedWe can see that there is a slight extra load time caused by having ES Module Shims on the page corresponding to an average of 6.5ms of extra load time, the time for ES Module Shims to initialize and run its feature detections.
For the most part, the performance is identical corresponding to the native passthrough being applied and the polyfill not engaging at all.
Baseline Passthrough with Throttling
As we start to throttle the network, the cost of the ES Module Shims bandwidth should then start to show due to its 12KB network download size
Throttling is performed to 750KB/s and 25ms RTT.
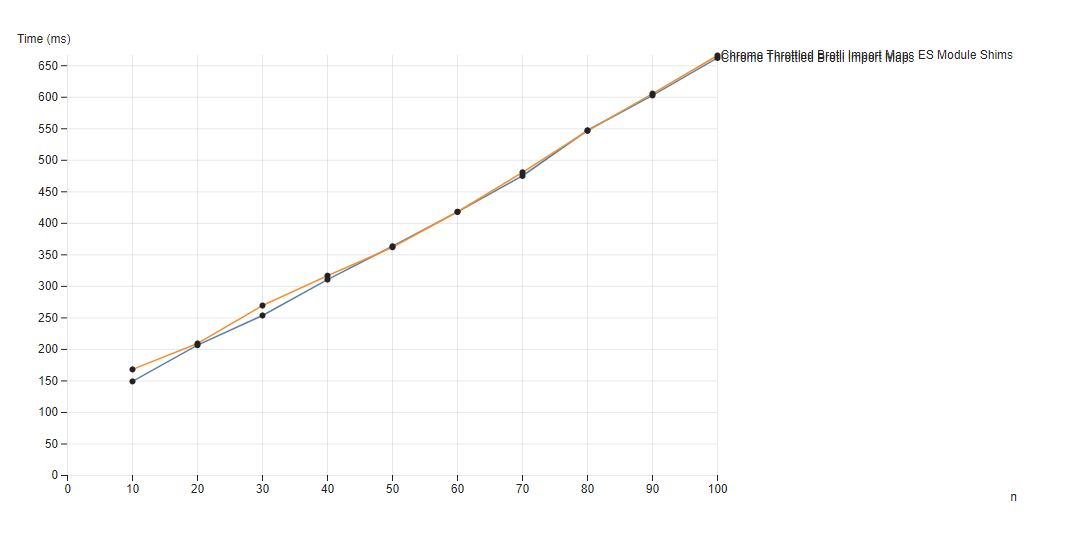
n number of samples loadedThrottling introduces some noise, but on average there is around 10ms extra loading time, where the expected load time for 12KB of JS on a 750KB/s network would be around 15ms (bearing in mind everything is in parallel so execution time fills in the network gaps).
We can therefore conclude that for the ~70% of users with import maps support, the polyfill effect on performance is mostly negligible, corresponding only to the 12KB download and some initialization time of usually never more than around 15ms.
Polyfill Performance
To test the cost when the ES Module Shims polyfill fully engages, we can't turn off native modules support in Chrome, but instead we can use the assumption that: The cost of loading a module graph with and without a small import map in use should be roughly similar.
Using this assumption in order to compare native loading performance to the polyfill we can use Firefox to ensure the polyfill engages, comparing the case with import maps and bare specifiers, which would engage the polyfill as import maps are currently unsupported in Firefox, against importing direct URLs which are natively supported (and without ES Module Shims at all in the page).
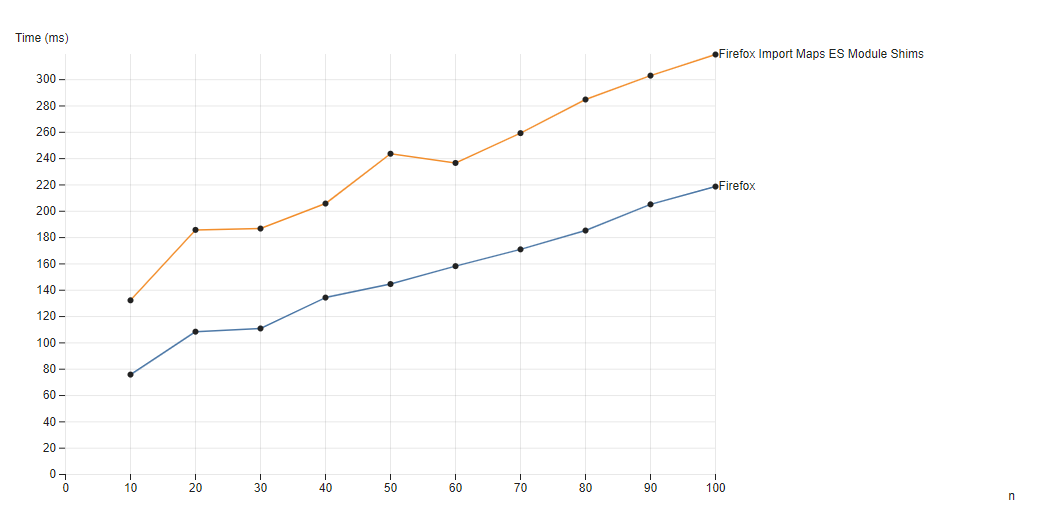
n number of samples loadedThe cost of the ES Module Shims polyfill layer in comparison to native shows a clear linear slowdown since all code is being executed through the ES Module Shims loader in the import maps case.
The linear correllation shows a polyfill cost of a 1.59x slowdown on average against native loading. Where 1MB of 100 modules loaded and executed in 220ms natively, it takes 320ms with the ES Module Shims polyfill (including all extra polyfill loading and initialization time).
Polyfill with Throttling
Again, checking the results on network throttled to 750KB/s and 5ms RTT:
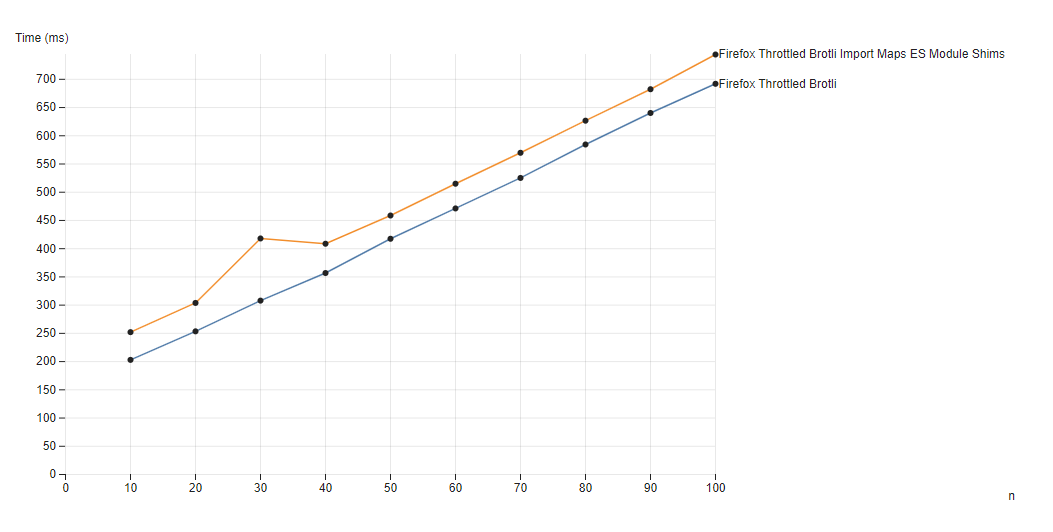
n number of samples loaded
From the data, the above gives an average of around a 1.14x slowdown under a throttled connection. Where 1MB of 100 modules loaded in 692ms natively, it took 744ms with the polyfill throttled. The overhead of the polyfill reduces with throttling since the network becomes the bottleneck, not the polyfill.
Import Maps Performance
The last question is if very large import maps (say 100s of lines) will slow down the page load since they lie on the critical load path.
To investigate this, we replace the previous simple two line import mapping, with a new import map that generates an import map line per sample case. So n = 10 would correspond to 20 distinct import map mappings that must be used going up to 200 lines for n = 100.
We use the throttled connection of 750KB/s and 25ms RTT since this is primarily a network question not a CPU one.
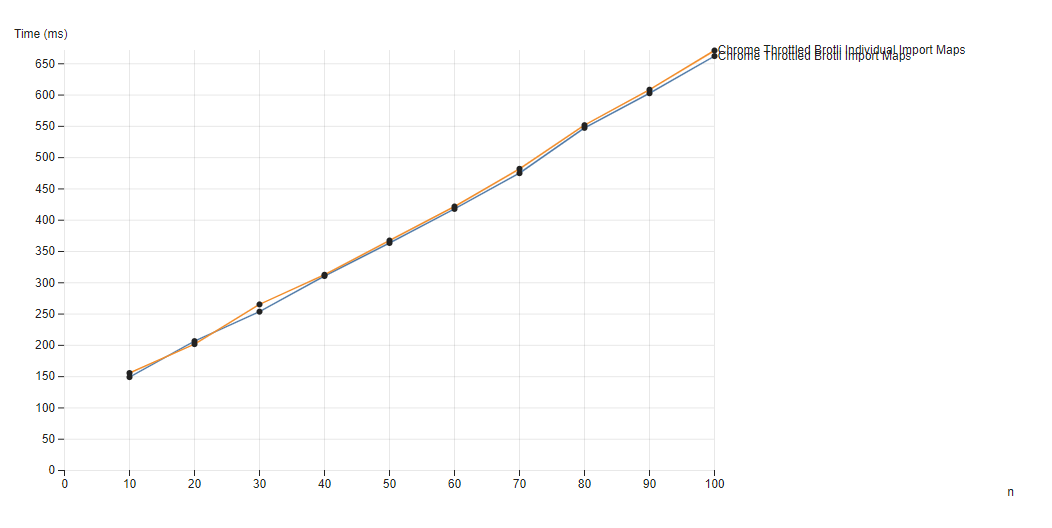
n sample (orange), varied over n number of samples loadedThe slowdown is very minor, at just under 10ms for the n = 100 case, corresponding to the minor additional download time of the larger map, demonstrating larger import maps have a negligible performance cost.
Polyfill Import Maps Performance
Finally to apply the same comparison as previously, but for Firefox and ES Module Shims, we would expect roughly the same dynamics without any surprises. Comparing an import map with two entries against one with two import map entries per sample n both loaded with the ES Module Shims polyfill:
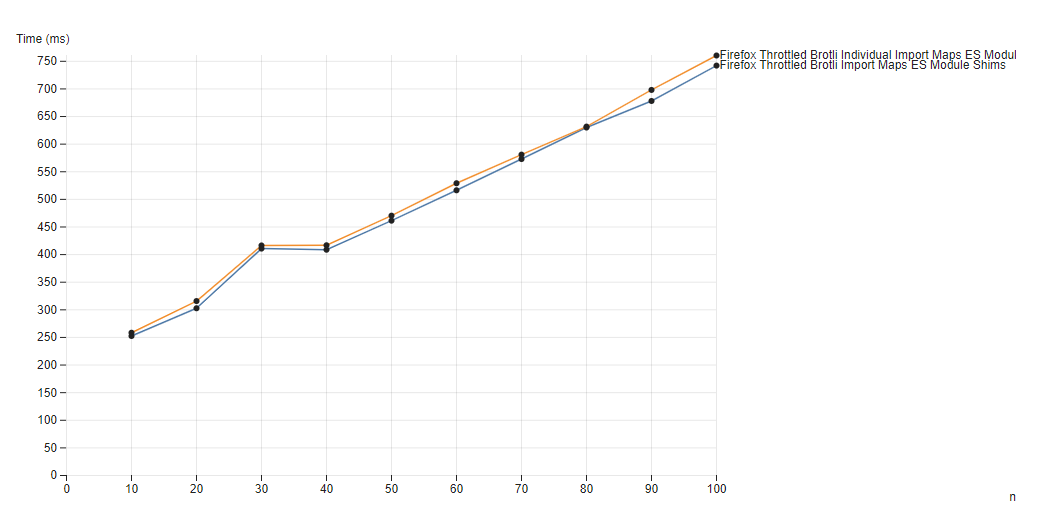
n sample (orange), varied over n number of samples loadedThe bump at n = 30 is likely an artifact of the throttling process itself.
The cost of loading a 200 line import map adds about 7.5ms in Chrome native and around 10ms for Firefox with the ES Module Shims polyfill to the page load time as expected on the throttled connection bandwidth - larger import maps are mostly low cost and with this cost as expected.
Project Future
ES Module Shims will continue to track new modules features on the horizon, and its baseline support target for the polyfill will naturally shift over time.
- CSS Modules and JSON Modules are current new native modules features that move the polyfill support baseline via an opt-in since they form static polyfill failures just like import maps.
- Supporting top-level await is tricky but should be possible with some lexer additions when the time comes to ensure wide support.
- Polyfilling module workers is unfortunately not possible in Firefox since dynamic
import()was never implemented for script workers (which is required per the first section to implement the loader). I believe that feature may be landing soon if it hasn't already so we would then have a polyfill path to inject loader hooks into module workers to possibly even polyfill features like module blocks on top of that as well. - Adding support for Wasm modules will be a primary aim for the project as well, possibly even combining with Wasm-related polyfills.
- Asset references would be fun to try polyfill as well.
As a rule for the project, only stable native features will be implemented when they're being implemented in browsers. Polyfill mode risks diverging from native otherwise.
Thanks for making it this far, you have no excuses not to use import maps now! (and benefit from superior granular caching.)